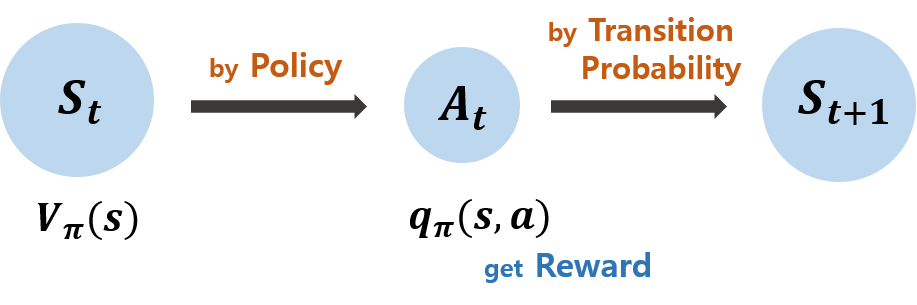
Markov Decision Process
대부분의 강화학습은 Markov Decision Process를 기반으로 만들어졌다고 해도 과언이 아니다. 따라서, 오늘은 강화학습의 기초 이론인 MDP에 대해 포스팅하고자 한다.
- 지난 포스팅까지 다룬 MAB문제 중 Contextual Bandits과 꽤나 유사하다. 이를 생각하며 공부한다면, 훨씬 이해가 쉬울 것이다.
- 이 포스팅은 이 블로그의 내용을 바탕으로 공부한 내용을 정리한 글임을 밝힌다.
0. Markov Process
이름에서도 알 수 있듯 Markov Decision Process는 Markov Process에 기반한다.
Markov Chain은 Markov property를 갖는 이산 확률 과정을 말한다.
-
이산 확률 과정: 어떠한 확률분포를 따르는 Random variable이 discrete한 time interval마다 생성되는 일련의 Process이다.
-
Markov property: \(t+1\)시점의 확률은 오직 \(t\)시점에만 영향을 받는다는 성질이다. (memoryless property)
-
\(P(S_{t+1}=s’\mid s_0,..,s_{t-1},s_{t}) = P(S_{t+1}=s’\mid s_t)\)
-
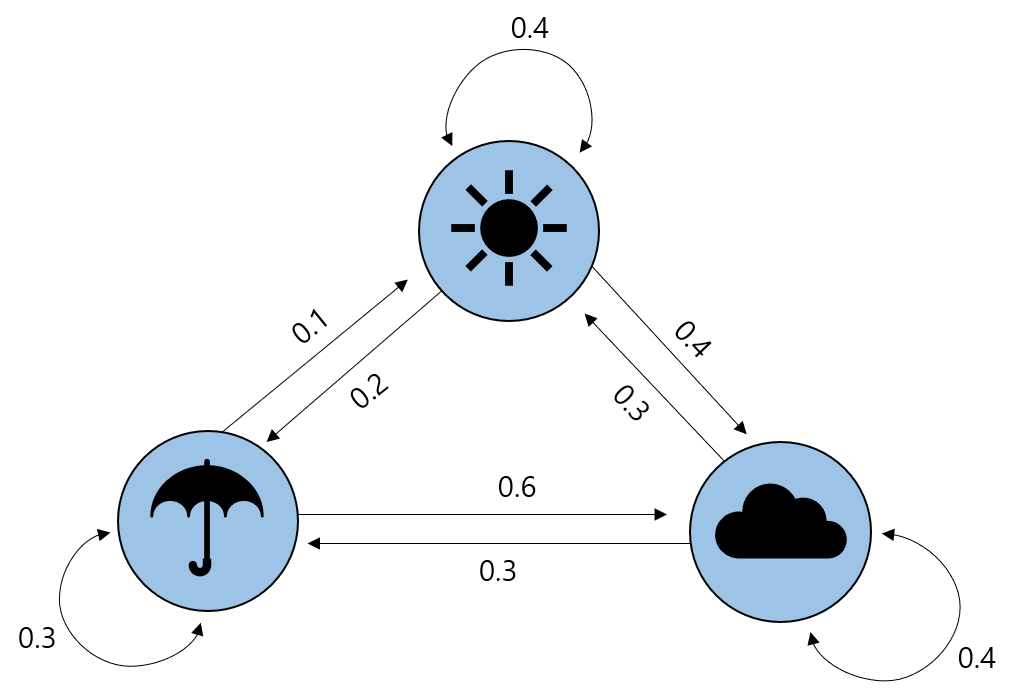
쉬운 예를 들어보자. 날씨에 영향을 주는 외생변수가 전혀 없다고 가정한다면, 내일 비가 올 확률은 오늘의 날씨에 따라 결정될 것이다. 오늘 흐리거나 비가 오면 내일도 비가 올 확률이 높을 것이고, 반대로 오늘 맑으면 내일 비가 올 확률은 낮을 것이다.
- 중요한 것은 어제의 날씨는 내일의 날씨에 직접적으로 영향을 주지 않는다는 사실이다. 어제의 날씨는 오늘의 날씨에 영향을 주었기 때문에, 어제 날씨에 대한 정보는 오늘의 날씨 정보에 모두 담겨 있다. 따라서, 어제 혹은 그 이전의 날씨는 내일의 날씨를 예측하는데 더이상 필요 없다.
-
-
Transition Probability Matrix: State간 이동(=transition)을 확률들을 표현한 Matrix이다.
-
각 원소는 State transition probability \(P_{s,s’}\)을 의미한다.
-
\(P_{s,s’}=Pr(S_{t+1}=s’ \mid S_t=s_t)\)

-
1. Markov Reward Process
- 일반 Markov Process는 State간 전이 확률만을 고려한 확률과정이라면, Markov Reward Process는 MP에 Reward의 개념을 추가한 확률과정이다.
- 해당 State로의 전이가 얼마나 가치있는 가를 고려한다.
- 각 State마다 Reward의 기댓값은 \(R_s\)로 표기한다.
- \(R_s=E[r_{t+1}\mid S_t=s]\)
- 이 값은 바로 다음 시점 \(t+1\)에서 얻는 Reward이기 때문에, immediate reward라고도 부른다.
- 그러나, \(S_t\)의 정확한 Reward를 알기 위해선, 즉시 얻을 수 있는 보상 뿐만 아니라 차후에 얻을 수 있는 보상도 고려해야 한다.
- 이때 차후에 얻을 수 있는 잠재성은 간접적인 Reward이기 때문에 immediate reward보단 낮은 가중치를 두고 평가해야 할 것이다.
- 즉, 현재 시점에서 멀어질 수록 보상의 할인율이 높아져야한다. - 위 컨셉을 Reward 수식에 반영하기 위해, discounting factor \(\gamma\)를 사용한다.
- \(\gamma \in [0,1]\) 이며, 미래가치를 현재시점의 가치로 변환한다.
- 이때 차후에 얻을 수 있는 잠재성은 간접적인 Reward이기 때문에 immediate reward보단 낮은 가중치를 두고 평가해야 할 것이다.
- Immediate Reward와 discounting factor을 통해 이제 Total reward값을 구할 수 있다.
- Total Reward: \(G_t= R_{t+1}+\gamma R_{t+2}+…=\sum_{k=0}^{\infty}\gamma^k R_{t+k+1}\)
-
Total Reward는 해당 State의 가치를 의미한다. 이를 Value Function으로 정리하여 표현한다.
-
State s에서 이동 가능한 state의 시나리오에 따라 미래 얻을 수 있는 모든 reward의 기댓값을 State s의 가치 \(V(s)\)라 한다.
-
Value function은 immediate reward와 future discounted reward 두가지 파트로 분해할 수 있다.
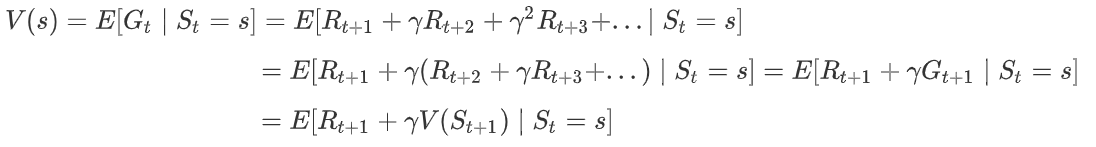
-
위 식은 후에 살펴볼 Bellman Equation이다.
-
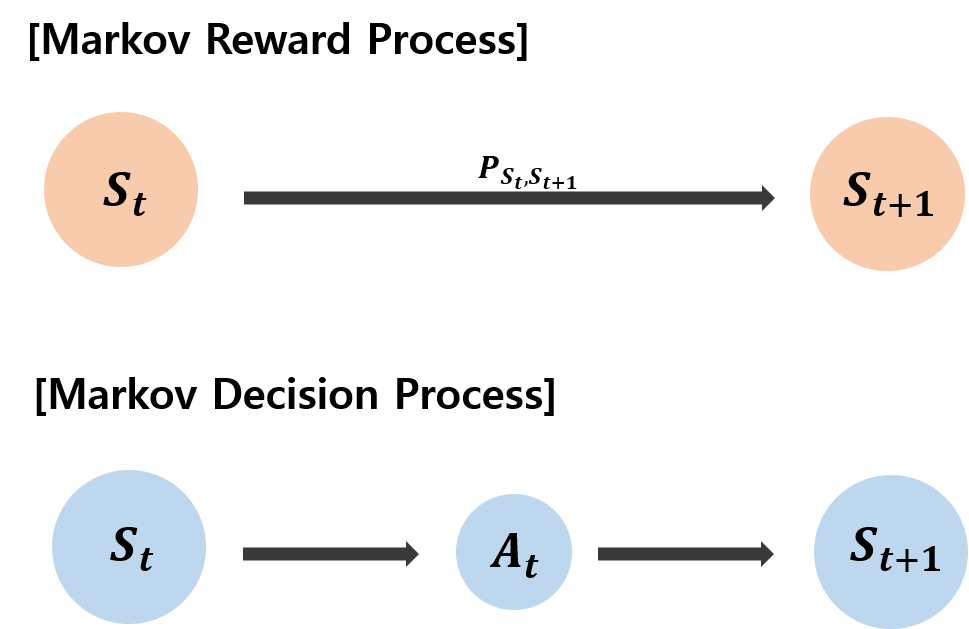
2. Markov Decision Process
-
위에서 살펴본 MRP에 Action변수를 추가한 것이 Markov Decision Process이다.
- 주어진 transition matrix의 확률에 따라 State를 이동하는 기존 방법이 아니라, State에서 Action을 취해 다음 State로 이동한다.
-
위에서 정의한 Action은 각 State마다 다른 의미를 갖는다. \(S_t\)에서 왼쪽으로 가는 Action을 취하는 것과 \(S_{t+1}\)에서 왼쪽으로 가는 Action을 취하는 것은 분명 다를 것이다. 따라서 우리는 State와 Action을 묶어 생각해야 하고, 이를 Policy로 정의한다.
- Policy: State에서 Action을 mapping하는 함수
- 해당 State에서 어떤 Action을 취할지 정하는 것이며, 확률로 나타난다.
- Reward를 최대화하는 Policy를 찾는 것이 강화학습의 최종 목표이다.
- \(\pi(a \mid s)= Pr(A_t=a \mid S_t=s)\)
[주의]
- Policy: state \(s\)에서 action \(a\)를 할 확률
- Transition Probability: state \(s\)에서 Policy에 의해 action \(a\)를 하고 그 결과 state \(s’\)로 전이할 확률
- \(P_{s,s’}^a = Pr(S_{t+1}=s’ \mid S_t=s, A_t=a)\)
- MRP에서 정의한 Reward도 action에 영향을 받기 때문에 아래와 같이 새로 정의할 수 있다.
- \(R_s^a = E[r_{t+1}\mid S_t=s, A_t=a]\)
Value Function
- MRP에선 해당 State의 가치를 표현하는 Value Function만 구했었는데, 이제는 Action의 가치를 표현하는 Value Function도 필요하다. Agent가 특정 action을 취함에 따라 선택하는 state 및 reward가 변하기 때문이다.
- State-value function: 해당 state \(s\)에서 policy \(\pi\)에 따라 얻게되는 reward의 총합
- \(V_{\pi}(s) = E_{\pi}[ G_t \mid S_t=s]\)
- Action-value function: state \(s\)에서 policy \(\pi\)에 따라 action을 취했을 때, 얻게되는 reward의 총합
- \(q_{\pi}(s,a) = E_{\pi}[G_t \mid S_t=s, A_t=a]\)
- State-value function: 해당 state \(s\)에서 policy \(\pi\)에 따라 얻게되는 reward의 총합
정리하자면 Markov Decision Process는 다음과 같다.